Principle
上一文中提到了截屏时候BufferQueue的特殊性,即SurfaceFlinger作为IGraphicBufferProduer的Bp端,Bn端则在WMS或Screenshot进程中。SF通过这个Bp代理,就可以实现dequeueBuffer和queueBuffer。但内部的实现却没这么简单。这里要涉及到Android Binder通信的一个特性,作者在此将它命名为Binder环。
要理解Binder环,最好先从Binder的线程模型说起。一般处理事务的线程,会被实现成一个死循环。当有任务请求到来,就被唤醒起来工作。如果所有请求都处理完毕,则会重新进入睡眠状态,等待下一个任务的到来。这就是Binder线程最基本的模型:
void IPCThreadState::joinThreadPool(bool isMain)
{
...
do {
processPendingDerefs();
// now get the next command to be processed, waiting if necessary
result = getAndExecuteCommand();
if (result < NO_ERROR && result != TIMED_OUT && result != -ECONNREFUSED && result != -EBADF) {
ALOGE("getAndExecuteCommand(fd=%d) returned unexpected error %d, aborting",
mProcess->mDriverFD, result);
abort();
}
// Let this thread exit the thread pool if it is no longer
// needed and it is not the main process thread.
if(result == TIMED_OUT && !isMain) {
break;
}
} while (result != -ECONNREFUSED && result != -EBADF);
...
}有了Binder线程以后,当前进程就可以作为一个server开始提供服务。但还有一个问题。如果这个Server需要同时为很多的Clients提供服务,如system_server,那必须保证该Server有一定的吞吐能力。为此引入了Binder线程池的概念。从上面提及的函数名joinThreadPool也可以看出,该函数将自身加入到线程池中,作为一个专门处理Binder请求的线程。线程池中可以有多个Binder线程,可以同时处理多路请求。并且考虑到动态负载,当线程池中的线程耗尽时(都处于工作中),就会spawn一个新的线程(BR_SPAWN_LOOPER)。当然用户可以给一个线程池的最大线程数设定限制。理论上说,当负载降低的时候,应该释放线程池中的线程资源,这是最完美的。但目前Android并未实现此功能。当然这也不是必要的,因为当系统资源不足的时候,lowmemorykiller就经常会拿这些空闲的Binder线程开刀。
有了线程池的概念之后,就可以理解Binder环了。说白了,这是Binder驱动在接收请求时做的一个优化。之所以称之为Binder环,是因为Binder通信不是简单的1:1,当进程A请求B完成某件事的时候,B可能又依赖于C。而在特殊场合下,C又可能依赖于A,所以就构成了一个环状结构。现在抛出了一个问题:当请求回到A的时候,由线程池中哪个Binder线程来负责处理请求?
最佳答案是A中最开始发起的Binder线程。

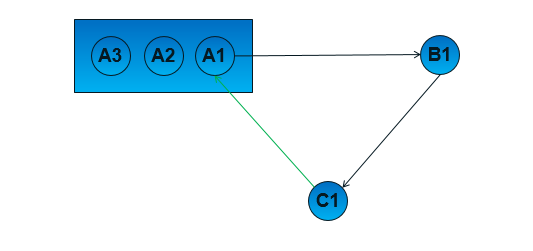
因为当请求回到进程A时,可以确定A1线程正在等待之前发送请求的回复,即处于阻塞状态,
所以我们可以顺便让A1起来干些别的事情。这种设计主要有两个优点:
-
更高效地利用线程池中的线程,避免不必要的线程增加,节省系统资源。
-
简化程序结构,特别是数据同步/锁保护,随机的Binder线程响应模式可能会增加锁的设计难度。
Binder驱动实现代码:
void binder_transaction()
{
...
while (tmp) {
if (tmp->from && tmp->from->proc == target_proc)
target_thread = tmp->from;
tmp = tmp->from_parent;
}
...
}Usage Scenario
在上一文中讨论的SurfaceFlinger截屏的实现中实际上就很巧妙地用到了Binder环。
直接引入实现的关键类:
class GraphicProducerWrapper : public BBinder, public MessageHandler {
大致的过程是:
-
一个Binder线程收到截屏请求之后,post一个消息让SF主线程处理
-
SF按照上一文的描述,做如下工作:dequeue一块buffer -> 合成 -> queueBuffer
但是特殊的是在第 1 步中, Binder线程同时创建了一个GraphicProducerWrapper类的实例,并把该对象放到消息里面一起post给了SF。SF在处理dequeueBuffer和queueBuffer的时候,正常情况下会调用一个IGraphicBufferProducer接口的Binder对象。但是我们注意到,GraphicProducerWrapper类正好也继承了BBinder,所以实际上SF主线程操作的是一个BBinder的transact函数,即GraphicProducerWrapper实现的transact函数:
/*
* this is called by our "fake" BpGraphicBufferProducer. We package the
* data and reply Parcel and forward them to the calling thread.
*/
virtual status_t transact(uint32_t code,
const Parcel& data, Parcel* reply, uint32_t flags) {
this->code = code;
this->data = &data;
this->reply = reply;
android_atomic_acquire_store(0, &memoryBarrier);
if (exitPending) {
// if we've exited, we run the message synchronously right here
handleMessage(Message(MSG_API_CALL));
} else {
barrier.close();
looper->sendMessage(this, Message(MSG_API_CALL));
barrier.wait();
}
return result;
}这里做的其实就是发了一个消息给之前的Binder线程,将dequeueBuffer或queueBuffer的请求又转回到该线程中。 而Binder线程的消息处理函数也呼之欲出:
/*
* here we run on the binder calling thread. All we've got to do is
* call the real BpGraphicBufferProducer.
*/
virtual void handleMessage(const Message& message) {
android_atomic_release_load(&memoryBarrier);
if (message.what == MSG_API_CALL) {
//the transact result needs to be held to let main thread know
result = impl->asBinder()->transact(code, data[0], reply);
barrier.open();
} else if (message.what == MSG_EXIT) {
exitRequested = true;
}
}这里真正地去做跨进程通信了。
总结一下,就是通过GraphicProducerWrapper在SF主线程的处理流中做了一个HOOK,看似在主线程中做了所有事情,实际上,真正的Binder通信请求又被委派到了最初的Binder线程中。引入这个Wrapper有什么好处呢?没错,就是利用了Binder环。如果用原先接收截屏请求的Binder线程来与请求方通信,那么就会构成一个Binder环,请求方只要再复用之前发CAPTURE_SCREEN请求的线程就可以了。
顺带一提的是,上一段代码在旧版本中有一处bug,即binder通信的结果result并没有保存。如果binder传输失败(对方进程死亡),因为没有正确返回错误码,会导致出现TOMBSTONE。在最新的代码中已被修复。